深入理解 Git 存储实质
技术点
Git
前置知识
-
引用(Reference)
引用是一种数据结构,用于快速寻址。指针是引用的一种实现,后也用于指代引用。数据库中的游标(Cursor)是一种特殊的引用,指向数据库中的记录行。
-
散列(Hash)
也称为哈希,是通过一系列散列算法将任意长度输入转换为固定长度输出的过程。其输出称为散列值。
-
校验和(Checksum)
校验和是数据处理和数据通信领域中,用于校验目的地数据完整性的一组数据项的和。通过校验和机制,可以保证文件不会在压缩或者传输中被更改或丢失部分数据。
重新认识 Git
Git 的本质是一套内容寻址文件系统
如果我们去列出 .git 文件夹里的文件,我们会看到如下的大致目录结构。
├── hooks/
├── info/
├── logs/
├── objects/
├── ref/
├── config
├── description
├── HEAD
├── index
└── packed-refs
Git 本质是一个内容寻址文件系统,也就意味着其核心部分是一个简单的键值数据库(key-value data store)。我们上述所列出的文件结构中,.git/objects 是 Git 的心脏,就是这个键值数据库。它同时也是我们所有提交数据最终汇总的地方。
你可以使用如下命令,简单生成一个 Git 仓库,然后查看其中的内容:
mkdir git-demo
cd git-demo
git init
find .git/objects
现在命令行界面将会打印出如下内容:
.git/objects
.git/objects/pack
.git/objects/info
那么,如果我们为其添加一条数据库记录呢?
echo 'test content' | git hash-object -w --stdin
这个命令执行后,命令行都将打印出相同的一串字符串:
d670460b4b4aece5915caf5c68d12f560a9fe3e4
此时,如果我们再执行
find .git/objects
那么,你的命令行将打印:
.git/objects
.git/objects/d6
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/pack
.git/objects/info
我们的 .git 目录中现在多出了一个目录和新文件。这就是 Git 存储我们代码的方式。借助这种方式,每次新增文件时,.git/objects 目录中将会将文件的原始数据与一种特殊的头部组合,然后将二者组合后的文件生成 SHA1 校验值作为键值对数据库的键,拆分为[目录]/[文件]两部分,按照如上方式进行存储。具体是2位作为目录的名称,剩余的38位作为文件名。 如果我们借助 git 底层的命令,那么很容易将对应的文件内容读出来:
git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4

感觉一头雾水?我们接下来将进行逐层解读。
使用校验和确保文件完整性
Git 中所有的数据在存储前都计算校验和,然后以校验和来引用。这意味着不可能在不知情的情况下变更 Git 仓库中的文件。同样,在传输和数据操作的过程中,Git 也可以第一时间发现出现的问题。这种设计也是 Git 哲学的一部分。 Git 存储时使用的计算校验和机制叫做 SHA-1 散列。这种散列生成的字符串由40个十六进制字符(0-9,a-z)组成,它是基于 Git 中文件的内容或者目录结构计算出来的。
// SHA-1 示例
5b28ea2c36ab26c652e8563bfa3f67032d3e135a
文件的三种状态
我们简单回顾一下 Git 的三个提交状态:
- 已提交(Commited):数据已经安全地保存到了数据库中
- 已暂存(Staged/Cached):数据已被标记,下次提交时将包含在其中
- 已修改(Modified):文件在数据库之外产生了修改,但还未进行任何其他操作
这三个状态分别对应文件的三个存储区域:
- Git 目录/数据库(.git directory)
- 暂存区/缓存区(Staging Area)
- 工作目录(Working Directory)
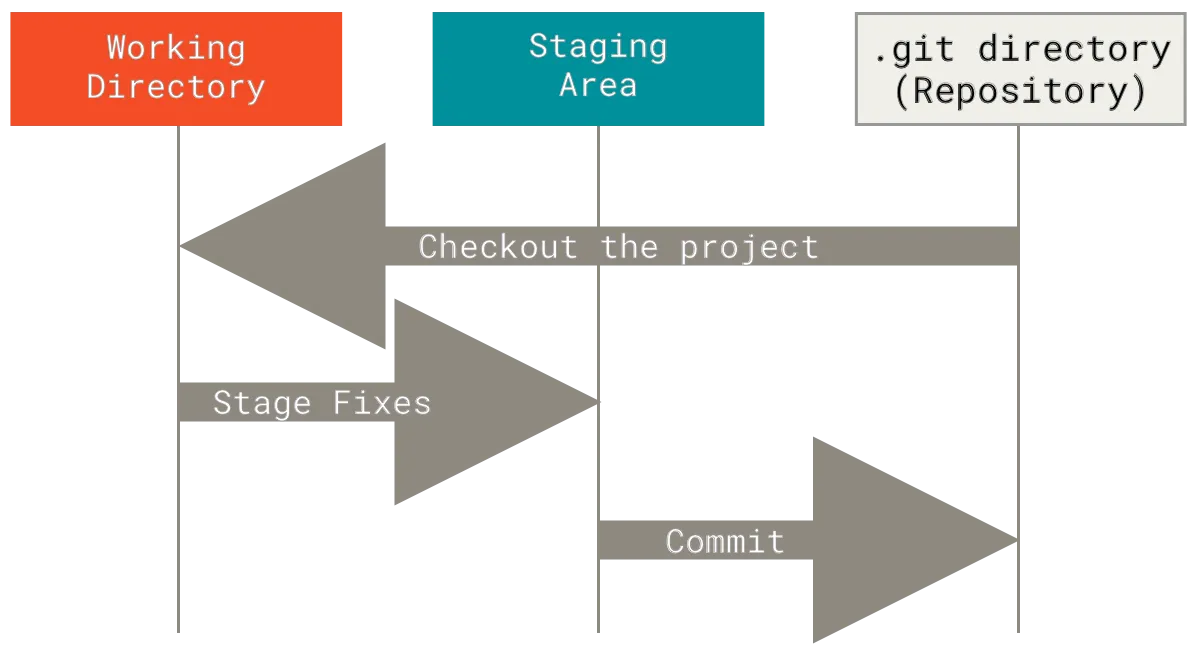
简单来说,三种状态之间的关系是:
- 代码进行了变更,但是还未执行 git add —— 已修改,文件位于工作目录
- 执行了 git add,但还是未执行 commit —— 已暂存,文件位于暂存区
- 执行了 commit —— 已提交,文件位于 Git 目录(数据库)
需要注意,git push 并不参与这一过程,其相当于是将本地的数据库推送至远端。
其中,暂存区在更为底层的 Git 功能讨论中也被称之为索引(Index),它将成为下一次提交(commit)的内容。
内部存储实质
列出我本地的某一 Git 数据库中的内容。我们可以简单地看到:
├── 00/
│ ├── 04845c9adc1ecdde40e1cfcfd3900739e4fcec
│ ├── 932c04469b5a6e98d129814d00ee096789ad2e
│ └── ...
├── 01/
│ ├── 00cfb6fd7bb9ab5ea2767fab936989a8e3c8a6
│ ├── 4ba562dfb69f8e9d839bed98d3e3cd4dd01941
│ └── ...
└── .../
在之前的章节中,我们通过 Git 底层命令的 hash-object 为其主动添加了一个简单的文本文件。但我们对于高层级 Git 如何使用这个数据库一无所知,那么,这些文件都是什么,都有哪些类别呢。 我们先来看一张摘自 Pro Git 这本书的图片,可以简单地认为每个圆角矩形为一个结点,如果我们只是观察一个 commit ,可以将其理解为树,正如 tree 的结点命名。全局来看,整个 Git 的数据结构是一个有向无环图(DAG,Directed Acyclic Graph)。
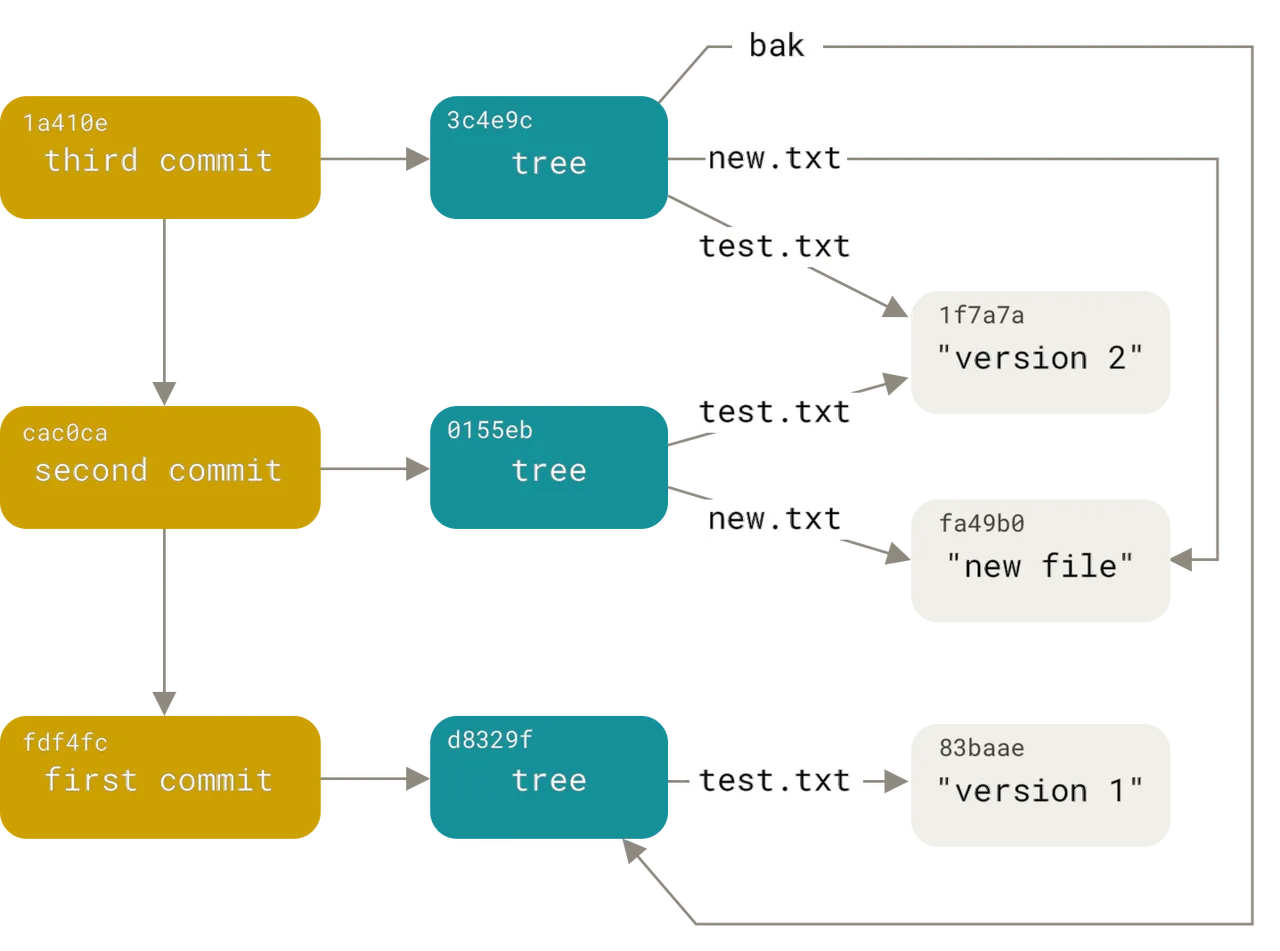 (上图引用自 Pro Git)
(上图引用自 Pro Git)
最左侧黄色的结点的是 commit 对象结点,我们称其为提交对象。中间是 tree 对象,我们称其为树对象。Git 创建这个对象以保存每个提交对应的文件快照,其中每个树对象包含一条或者多条 tree entry(树对象记录),每条记录有含有一个指向数据对象或子树对象的 SHA-1 引用。最右侧的是数据对象,存储的是文件原始数据和特殊头部的组合。 我们使用 git cat-file -p 提取各种对象的存储数据,可以发现其格式如下:
- 如果是提交对象,那么:

可以看到,其包含了两个父结点和一个树结点,同时带有一些提交信息。 接下来,我们继续去观察树结点。
- 树节点的结构如下:

其中包含了若干个树结点和数据结点(Blob 结点)。如果是树节点下的树结点,那么其就是一个目录,如果是数据结点,那就是一个文件。
- 文件结点的内容如下,这就是特殊头和实际内容的组合:

此外,标签分类中的附注标签也具备其自己的数据结构。
分支即引用
如果观察得到,可以发现 .git/refs/head 中存在一些和我们的分支相同名称的文件。

我们去查看其中某一分支的内容,可以发现,其中存储的是一串 SHA1 值。这就是这个分支现在 HEAD 的指向的提交对象。也就是说,HEAD 本质是一个引用,引用了 Git 创建的提交对象。每个分支都有自己的 HEAD 引用。

你可以发现 .git/refs 中还有其他的文件夹:

我们这里看一下 remotes 中的内容。
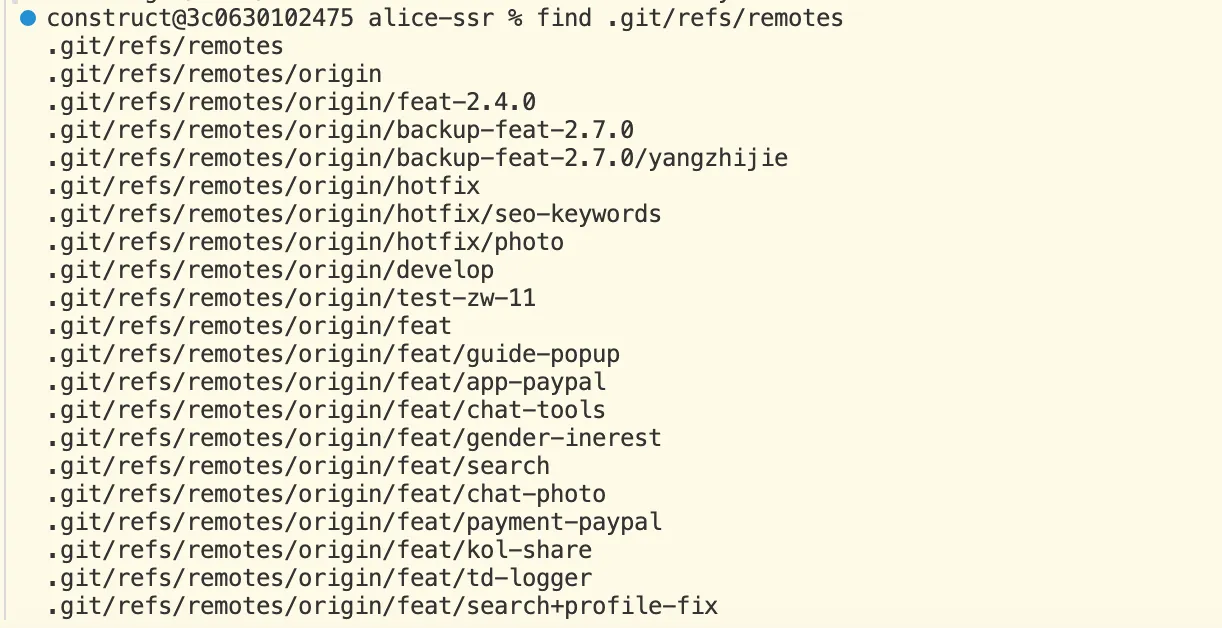
其实,远端分支也是使用了这种引用的形式保存,它们和本地分支之间存在一个 upstreaming 的关系。
同样,对于轻量标签,Git 内部也采用了这种存储方式。
一旦添加数据,基本不会丢失
和其他的 VCS(Version Control System)一样,如果未提交更新,Git 也很有可能丢失修改的内容。
但 Git 作为分布式的版本控制系统,为每个仓库的使用者创建了一个副本,我们还可以创建多个分支,使用 Git 时并不会把提交 commit 作为一种有阻力的内容(因为在自己的副本修改时,不需要考虑代码合并冲突的问题)。一旦提交快照到 Git 中,就很难再丢失数据,特别是在这个分布式的多仓库存储的情况下。 基本上我们常用的 Git 操作,都是往 Git 数据库添加数据,很难去从 Git 数据库中删除数据。因此其几乎不会执行任何可能导致文件不可恢复的操作。 想一想我们经常使用到的命令:
git add
git commit
git checkout
git branch
git pull
git fetch
git clone
如果进一步追究,那么有:
git rm
git reset
git checkout -- [file]
这些命令,可能存在丢失数据的风险。但注意,也仅仅是可能。 现在,我们可以推断 checkout 和 reset 的实质。
Checkout 和 Reset 的实质
当我们进行 checkout 的时候,如果:
- checkout 的是一个文件,那么将仓库数据库中的文件签出,在工作目录和暂存区复制一个副本
- checkout 的是一个提交,那么将仓库数据库中对应提交结点保存的树结点中所有涉及的文件全部导出,为所有文件在工作目录和暂存区复制一个副本
如果是执行 reset,其操作的是各个分支的 HEAD 引用位置,因此
- 如果是某一分支,那么 Git 会去查找 .git/refs 目录中对应的分支文件,从中读取其对应的引用
- 如果是 HEAD 加辅助标志,如 HEAD~3,那么就将把当前分支的 HEAD 移动到指定的提交结点上
- 如果是某一提交的 id,那么就会将当前分支的 HEAD 移动到指定的提交结点上
同时,根据尾随参数的不同,如 —hard、—soft 决定了对工作目录和暂存区中文件的处理方式。前者使其三个存储区文件完全一致,清理工作目录和暂存区;后者不操作工作目录和暂存区。 默认尾随为 —mixed,这个参数允许对暂存区的操作。
什么时候会丢失数据?
现在,回过头来看我们列出的三种危险指令:
- git rm:这个命令使得文件从暂存区和工作目录中移除,一旦提交到 Git 目录,那么将不会被影响
- git reset:这个命令将调整引用的指向,并不主动删除结点
- git checkout: 这个命令只负责将数据库中的文件同步到暂存区和工作目录,也不会主动删除已提交的数据
使用 Git 完成工作流
一个真实场景的例子
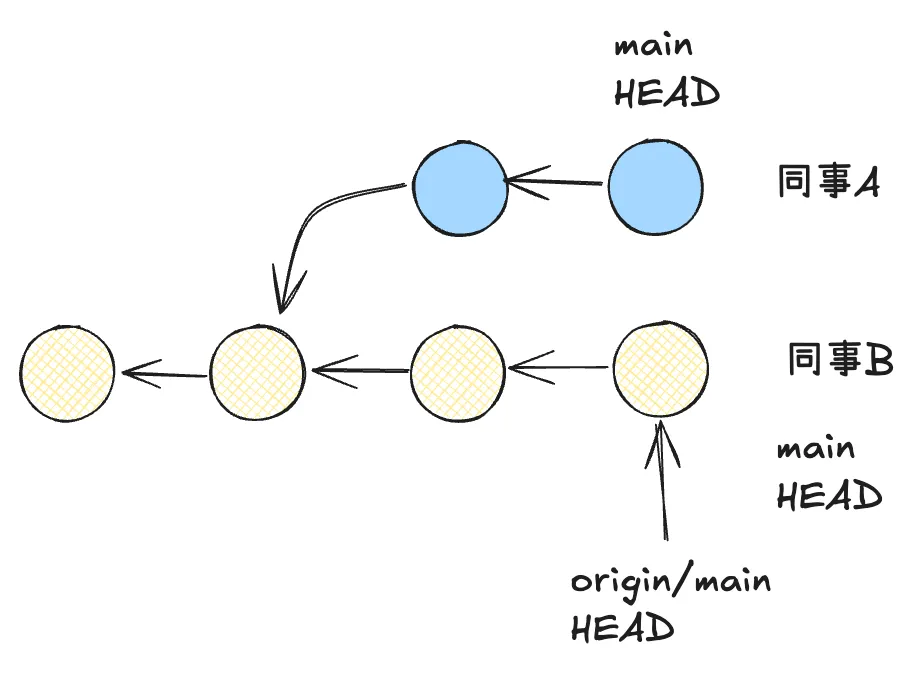
试想有这样一个场景,假设我们只有一个远程分支,同事 A 使用 git checkout 创建了一个远程分支的副本,然后在这个分支上进行修改。随后有一个同事 B,需要开发另一个功能,于是他针对于这个远程分支进行了拉取,然后在本地修改。此时,Git 的数据库就有三个副本。假设分支为 main,那么将会有三个 main 分支。
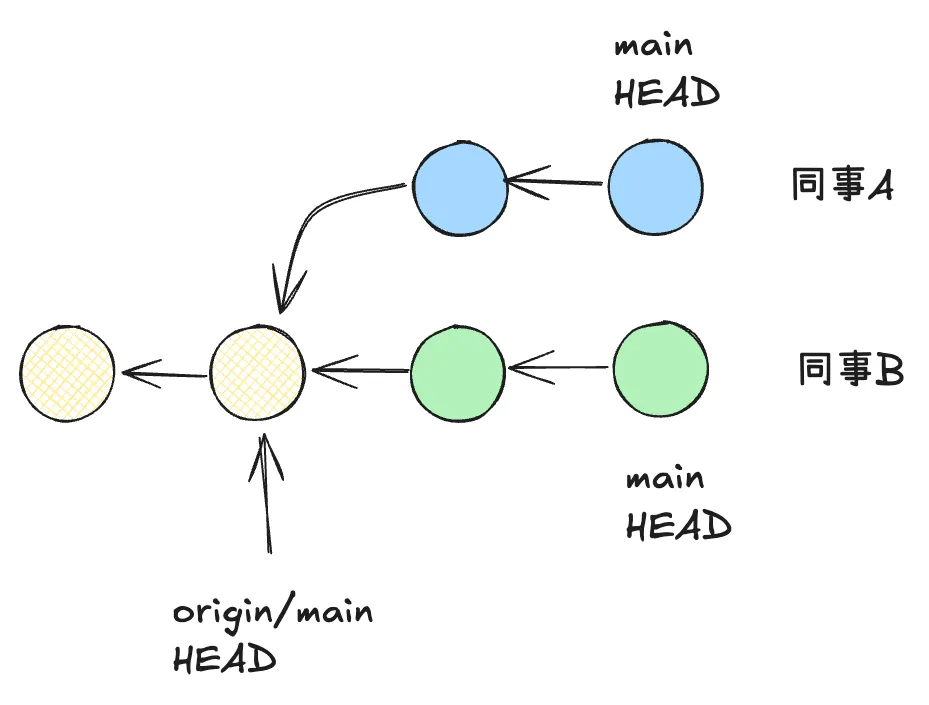
如果想要将双方的提交都提交到远程分支(远端仓库)上,肯定会产生冲突。
同事 A 想要提交到远端,使用了 git push,远端成功进行了更新。那么同事 B 也想要将变更提交到仓库,同样执行 git push,就会报错,提示两端数据冲突。这时候我们就有了两种选择,合并(Merge),或者变基(Rebase)。注意,这里所有人的工作分支都是中央分支,或者说其工作分支的 upstream 是中央分支。至于具体如何解决我们稍后再回过来解答。
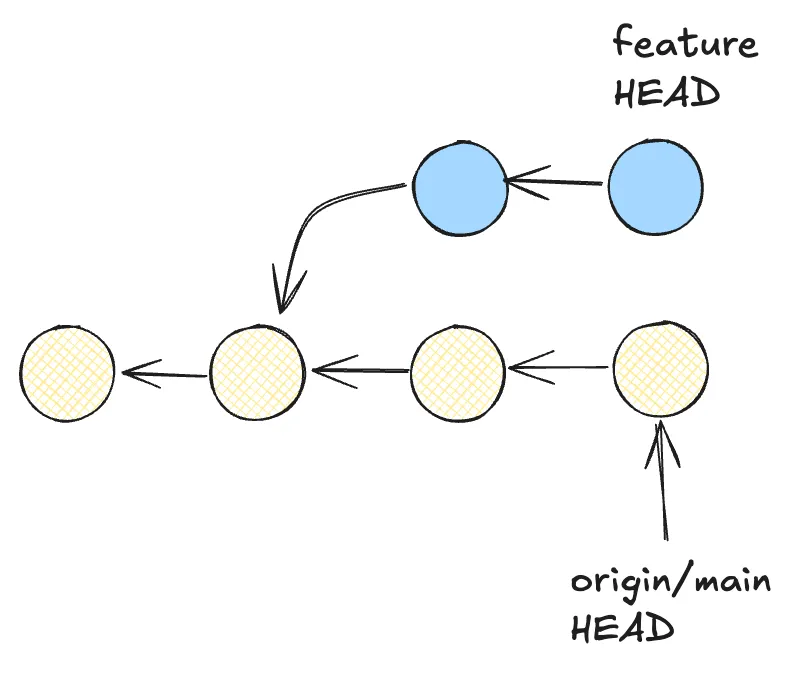
两种工作分支整合的方法
举个简单的例子,如果我在 feature 分支上进行工作,已经有了数个提交(commit),我想要将工作提交到中央分支 main 上,但 main 分支已经有了其他同事的变更。此时应当如何进行整合分支呢?
合并(Merge)
合并是一种最简单也不容易出错的工作分支合并方法。具体命令只需要切换到对应的分支,然后使用 merge 即可。具体命令是:
git checkout main
git merge feature
或者,可以使用缩短的语法:
git merge main feature
这样,它就可以在不破坏被合并的分支(我们这里是 feature)和不改变提交信息的前提下,将工作提交合并到目标的分支之上(这里是 main)。这就是合并(Merge)最大的好处,易于追溯历史提交的记录。但代价是,当工作分支足够多时,可能会有非常庞大难以理解的 Git 分支图(非线性的)。
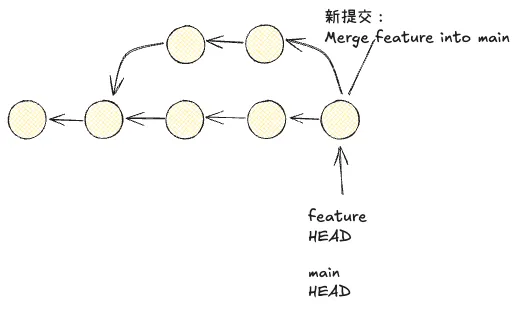
其中,当代码未产生冲突时(main 分支的 HEAD 指向的是 feature 分支提交结点路径上的某一结点),那么将可以进行 Fast-Forward。简而言之,就是将数据库同步,仅移动远端 main 分支的 HEAD 引用到 feature 的 HEAD 引用所引用的结点。 是否允许 Fast-Forward 视团队的规范而定,部分团队希望能够保留每个分支存在的痕迹,为此,可以执行合并而禁止使用 Fast-Forward:
git merge main feature --no-ff
变基(Rebase)
另一种令人望而生畏的冲突解决方法是变基(Rebase)。为什么令人望而生畏——很多开发者误以为,变基之后,原分支改变了,原有的提交数据就丢失了,实际并不是这样的。我们经过前几个章节的了解,也充分明白 Git 存储的本质,提交数据在处于悬空状态(dangling)时,仍会在执行垃圾回收存在一段时间。默认 Git 的垃圾回收时间是比较长的,足够你在发现问题前回溯分支。 使用如下命令即可进行变基:
git checkout feature
git rebase main
要注意,变基使用的 checkout 分支刚好与合并的相反,它是将当前分支(feature)和目标分支(master)最近公共父结点之后当前分支(feature)的结点逐一处理完重新添加到目标分支(master)最新的提交之后。也就是丢弃旧的提交(不是删除,仅仅是不使用),根据原提交应用新的提交。因此,原有分支将不再保持原样,原来的提交信息也会被更新。
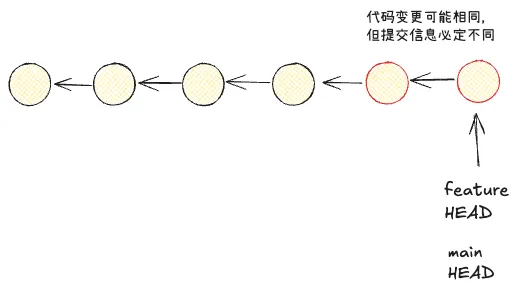
这一方法的优点在于,即使代码存在冲突,也可以实现完美的线性提交记录。缺点在于,变基后很难去追溯提交历史,变基时,提交时间有可能被更新。 此外,比学会变基更重要的,学会什么时候不使用变基。 如果提交存在于你的仓库之外,而别人可能基于这些提交进行开发,那么不要(对这些提交)执行变基。 简而言之,不要对公共分支进行变基,例如在 main 分支上执行 git rebase feature。
变基存在的问题
还是刚才的例子,但做一个补充。假设我们有一个同事 C,他基于 feature 分支开发,这个分支上有 0、1、A 三个提交。他完成开发后,将这分支推送到了远端。 同事 A 在 feature 的前一版本快照(只有 0、1)上进行了开发,新增了 B、C 两个提交。 此时,分支是这样的结构,如果同事 A 推送到远端,必然会产生冲突。
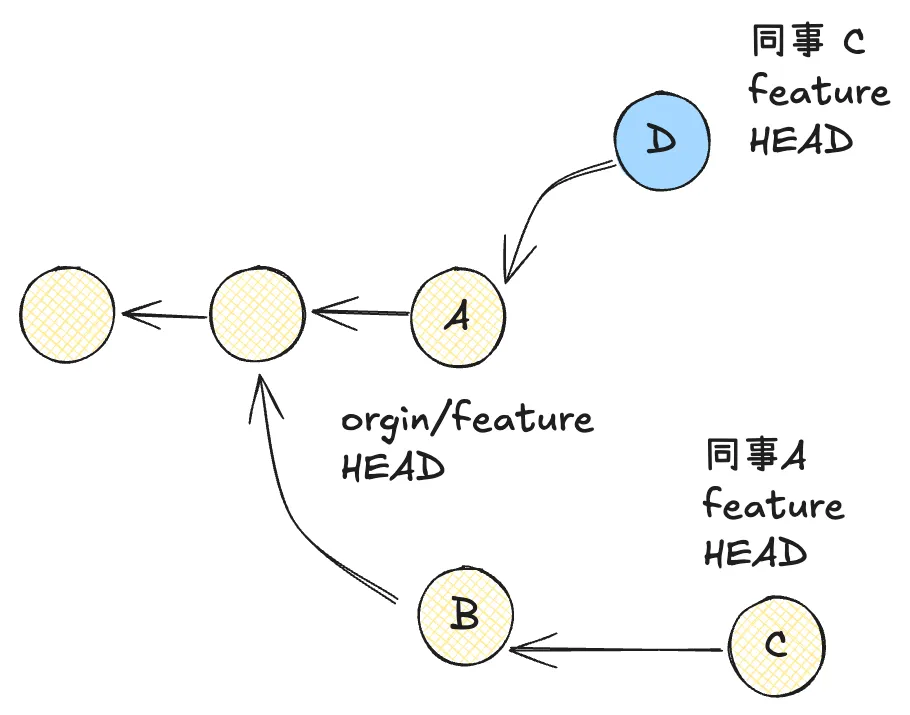
这之后,同事 A 想要推送到远端仓库,需要解决冲突的问题。于是同事 A 针对同事 C feature 分支做了变基,让 feature 的公共提交 A 重新应用在了同事 A 的分支上产生了提交 A’,然后将 feature 推送到了远端仓库(其中 A 和 A’ 是代码相同的变基前后的不同提交)。
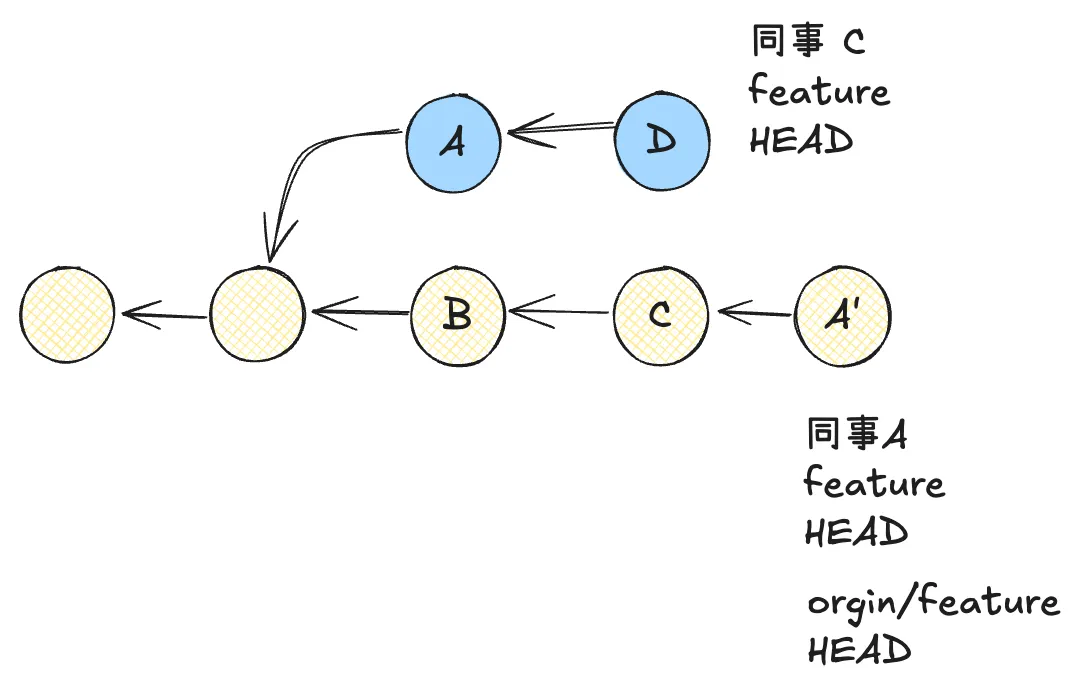
阶段 1. 初始化
git init
git checkout -b feature
echo 0 >> 0.txt
git add . && git commit -m '0'
echo 1 >> 1.txt
git add . && git commit -m '1'
git checkout -b feature-A
echo B >> B.txt
git add . && git commit -m 'B'
echo C >> C.txt
git add . && git commit -m 'C'
git checkout feature
echo A >> A.txt
git add . && git commit -m 'A'
git checkout -b feature-C
echo D >> D.txt
git add . && git commit -m 'D'
阶段 2. 错误的 rebase
git checkout feature
git rebase feature-A
阶段 3. 错误地进行 rebase
git checkout feature
git merge feature -C
阶段 4. 如何修复
git reset HEAD^ --hard
git checkout feature -C
git rebase feature
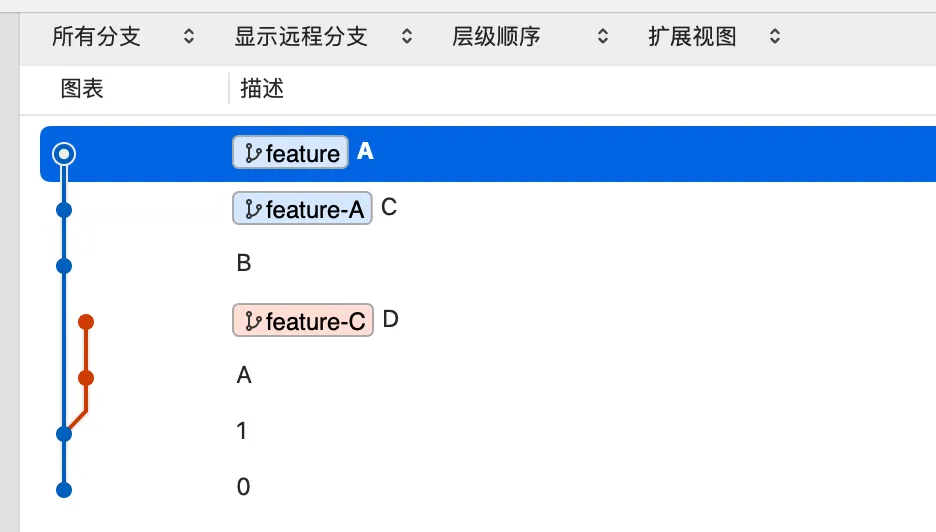
阶段 2 产物:
阶段 3 产物:
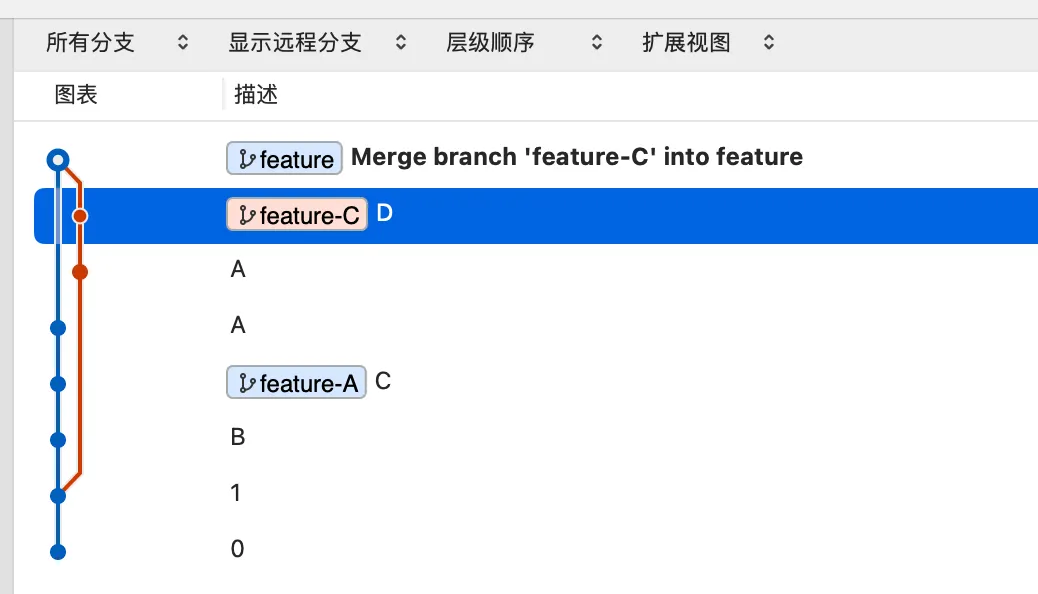
我们使用这一段命令对 Git 进行一个初始化(你如果同样使用可视化工具,可能需要变更一些文件,使得它们可以正确地显示分支图),直至阶段 3,此时就会生成一个错误 Rebase 后,其他人合并之后的分支图。 其中,两个提交消息为 A 的提交包含的代码是完全相同的,但是仍然会被提交到仓库中。如果不去处理,那么 Git 就会认为是两个不同的提交。 这时候,这两个提交代码修改相同、信息相同、甚至可能提交日期相同,其他不知情的协作者势必会感觉到困惑,同样,思考一下项目扩大后的情况,这种奇怪的分支,也会对分支图的阅读产生很大的影响。 这种情况还是可以解决的,这两个看着相同的提交通过阶段 4 的命令可以进行修复。
阶段 4 产物:
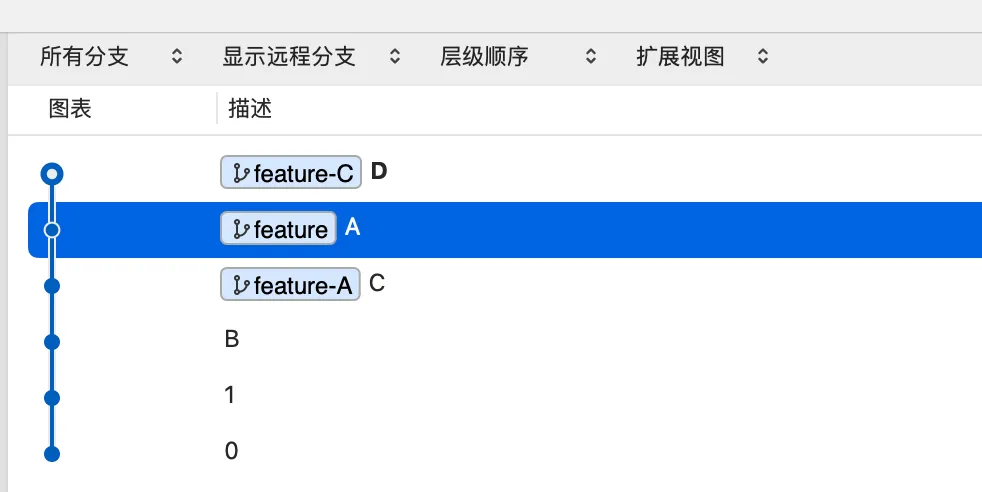
Git 会计算每次提交之间的差异值,生成对应的 patch-id,如果 patch-id 相同,则可以认为是两次相同的提交。此时如果满足这一条件,那么变基之后就会恢复正常。 但是,如果有开发者在变基时对提交做出了修改,那么这个方法就无法修复这个问题。因此,绝对不要在公共分支上进行变基,如果有错误的提交,可以通过 revert 进行修复。或者,如果得到了其他公共分支使用者的同意,此时才可以对公共分支进行变基。
交互式变基
一般情况下,我们执行 git rebase,可以满足大部分的需求。这个操作是通知 Git 进行自动变基,总的提交数量可能是不变的。 如果执行 git rebase -i,我们可以使用变基的另一杀招,交互式变基。如果不带参数进行变基,那么将自动确定需要变基的结点,通过命令行编辑文本的形式列出对应项。 pick 33d5b7a feat: 添加 A 组件 #1 pick 9480b3d feat: 添加 B 组件 #2 pick 5c67e61 feat: 添加 A 组件的接口 #3 你可以通过修改文本中的信息来整理提交的内容,甚至可以将多个提交压缩为单个提交,只需要将前置结点的 pick 改为 fixup,它就会在退出编辑时将其整合到后一个提交之中。 一个参考的命令清单如下,引用自 Pro Git 一书:
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup <commit> = like "squash", but discard this commit's log message
# x, exec <command> = run command (the rest of the line) using shell
# b, break = stop here (continue rebase later with 'git rebase --continue')
# d, drop <commit> = remove commit
# l, label <label> = label current HEAD with a name
# t, reset <label> = reset HEAD to a label
# m, merge [-C <commit> | -c <commit>] <label> [# <oneline>]
# . create a merge commit using the original merge commit's
# . message (or the oneline, if no original merge commit was
# . specified). Use -c <commit> to reword the commit message.
举个例子,我们需要合并刚才的多个提交,那么就可以将提交信息改为:
fixup 33d5b7a feat: 添加 A 组件 #1
fixup 9480b3d feat: 添加 B 组件 #2
pick 5c67e61 feat: 添加 A 组件的接口 #3
如果需要修改提交的信息,那么可以使用:
pick 33d5b7a feat: 添加 A 组件 #1
edit 9480b3d feat: 修改消息 #2
pick 5c67e61 feat: 添加 A 组件的接口 #3
之后会为我们进行引导,提示我们如何继续进行变基,按照指引操作即可。
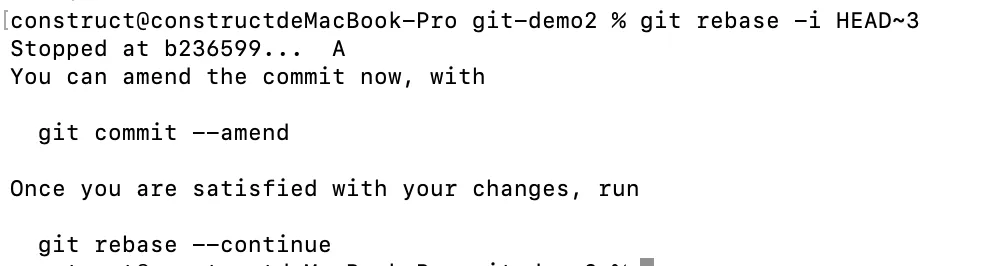 其中,git commit —amend 是修订上一个提交的命令,这里由于变基,此阶段执行到了提交刚才我们修订的 9480b3d 提交后。一旦完成修改,继续 git rebase —continue 即可。
如果想要终止变基过程,那么可以执行 git rebase —abort。
如果你使用的是 VSCode 或者 WebStorm 等 IDE,其左侧栏一般会有对应的提交状态和信息。
如果合并或变基时出现了冲突,则合并后的文件的临时版本如下:
其中,git commit —amend 是修订上一个提交的命令,这里由于变基,此阶段执行到了提交刚才我们修订的 9480b3d 提交后。一旦完成修改,继续 git rebase —continue 即可。
如果想要终止变基过程,那么可以执行 git rebase —abort。
如果你使用的是 VSCode 或者 WebStorm 等 IDE,其左侧栏一般会有对应的提交状态和信息。
如果合并或变基时出现了冲突,则合并后的文件的临时版本如下:
\<<<<<<< HEAD
1231231
=======
3234242
\>>>>>>> feature
确定最终需要保存的版本,移除额外多出的 <<< | >>> | === 所在的行,将其提交到暂存区,就可以就正常合并了。
常见的工作流
有一个观念非常重要,Git 是灵活的,其相关工作流应该适应团队而变化。 这里简单介绍一下常见的工作流,方便查阅和了解。
集中式工作流
集中式工作流常见于 SVN 等 CVCS(Central Version Control System)之中,其使用单一的中央分支作为所有变更的单一入口点。所有的代码变更都要提交到单一的分支之中。
一般在集中式的工作流之中,解决冲突只允许有变基一种方法,作为直接的结果是,产生的是极为优雅的线性提交记录。
此中工作流每当提交变更时,需要立即解决与其他协作者代码之间的冲突,否则无法提交到代码仓库之中。一般地,实践中需要针对于每个模块的功能做好控制和限制,团队的管理者会要求开发者定期同步代码到主分支中,防止难以解决的冲突。
此种工作流的优点在于,非常适合小型团队的快速迭代,但随着团队规模的扩大,对于冲突和提交的管理就逐渐极为重要,否则易于成为团队开发的瓶颈。同样,管理得当的大型团队使用 SVN,即集中式工作流也完成了许多有建树的工作。其缺点在于,不方便在集成功能前针对于新增功能进行代码审查和深入讨论,也不利于将功能拆分出来提供一份简单的代码,需要维护好各个模块的控制。
此类分支还有一些基于 Git 的变种,比如个人独立出自己的分支,定期向中央分支(或其镜像分支)提交等。
功能分支工作流
功能分支工作流背后的理念是,所有的功能开发都应该在专有分支进行,而不应该在主分支上进行。这也就意味着所有开发者都可以有专有的工作分支,不会因为工作而使得主分支包含损坏的代码。这也是一种比较适合用于持续集成(CI,Continuous Integration)的分支模型。 同样,这种分支工作流在完全合并到主分支(比如 main)之前,提供了进行代码审查的机会。开发者完全可以在合并到主分支之前利用 Git 托管平台开启 Pull Request 或者 Merge Request,让同行对代码进行分析,然后轻松地对彼此的工作发表评论。 此外,此分支模型的一大优点是,所有功能的开发过程都是有历史分支进行记录的,这样,对于各个功能的整合也相对轻松,很容易可以决定发布时需要进行的功能整合。
功能分支工作流专注于分支的模式,对 Git 工作流的分支方面做了要求,其要点在于:
- 使用不同分支开发特性,与主分支相分离
- 能够借助代码审查促进团队之间的协作 其功能分支模型可以应用于其他的工作流之中,比如 Git Flow 工作流等。
Git Flow 工作流
这个工作流值得一个专题来讲解,使用如下类型分支进行工作:
- Main - 主分支
- Feature - 特性分支
- Hotfix - 热修复分支
- Release - 发布分支
- Develop - 另一主分支,用于开发
其核心特征是有两个主分支,main 以及 develop。 开发者基于 develop 进行派生和协作,使用 feature 分支开发功能。当功能开发完毕后, feature 合并回 develop。 之后,在 develop 分支达到发布要求后派生 release 分支,此后所有的问题修复都基于 release 进行,不在 feature特性分支上进行。 最后,充分确认和代码审查后,release 进行发布到线上,代码合并到 master。这一步通常会压缩提交,确保清晰的 master 分支,此后,在 master 上进行版本的标注(标签)。 如果需要进行紧急修复,那么从 master 拉取热修复分支 hotfix,使用 hotfix 部署特殊的 hotfix 环境进行测试。最终,修复完毕合并到 master 和 develop 分支。 此外,可能存在 support 分支用于代码的合并,由于时间和篇幅原因这里就不展开描述,感兴趣可以查看这篇文章,结合 git-flow 备忘清单进行学习。
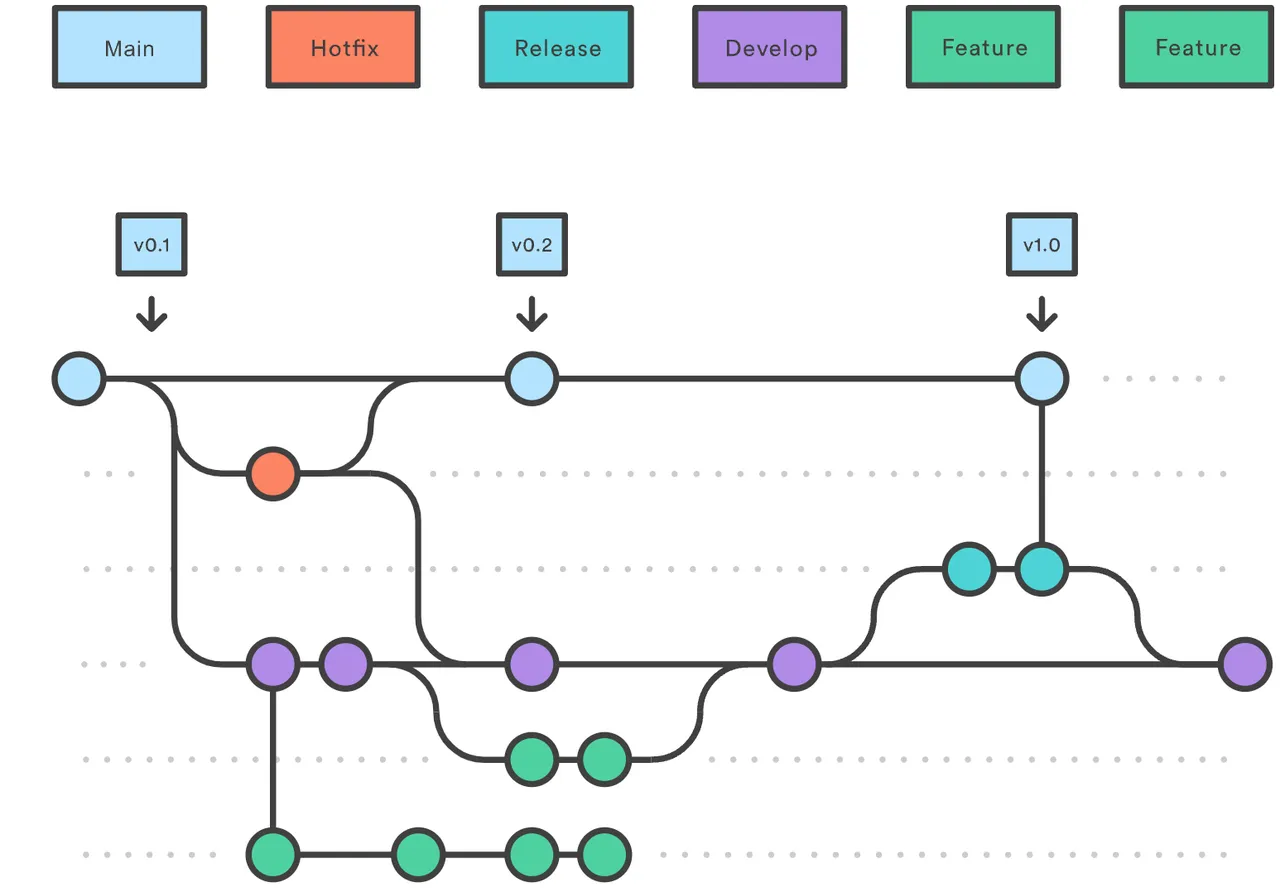 (上图引用自 Atlassain)
(上图引用自 Atlassain)
其他工作流
- 集成管理者工作流
- 主管与副主管工作流
- 创建新拷贝工作流(基于 Fork,本质也是集成管理者工作流)